


Mastering Stable Diffusion: From Text Prompt to Latent Space Explained
Generative AI has exploded in the last few years. Tools now turn simple words into stunning images. Stable Diffusion stands out as a free, powerful option for text-to-image creation. You can access it on platforms like Hugging Face without any cost. This model lets anyone, from beginners to pros, generate art or visuals from descriptions. We’ll break down how it works, step by step, so you can use it for fun or business.
Understanding Generative AI and Diffusion Models
Understanding Generative AI and Diffusion Models:
What Are Diffusion Models?
Diffusion models form one branch of Generative AI. They differ from large language models like those for chat. These focus on creating images from text inputs. Think of it like perfume sprayed in a room. At first, the scent hits hard in one spot. Over time, it spreads evenly everywhere. That’s diffusion: high intensity fades into low intensity. In AI, this process builds or cleans images from noise.
Models like these power computer vision tasks. You input a text prompt, and the system outputs a picture. They handle image generation and even video basics. Time plays a key role here. The model works in small steps, adding or removing details gradually. This makes results smooth and realistic.
The Physics Concept Applied to Computer Vision
Diffusion borrows from physics. Imagine ink dropped on cloth. The spot darkens first, then color spreads out. Edges blur as it thins. In computer vision, this applies to pixels. Each pixel holds color data, like red, green, or blue. The model shifts from messy noise to clear patterns.
These tools fall under computer vision in AI. Vision deals with seeing and making sense of images. Diffusion models shine here for creation. They avoid heavy motion, focusing on steady changes. Time steps matter: short intervals build the image bit by bit. This keeps the process controlled and predictable.
You might wonder why not just draw directly? Diffusion ensures variety and quality. It mimics natural spread, leading to diverse outputs from one prompt.
Stable Diffusion vs. Generic Diffusion Models
Stable Diffusion is a specific type of diffusion model. It’s optimized for speed and low resource use. Older models process every pixel fully, which takes huge power. Stable Diffusion compresses images first, cutting compute needs by up to 48 times. This means faster results with less hardware.
Latency drops too—images generate in seconds, not minutes. Image compression happens in a smart way. It keeps key details while shrinking data size. For users, this means easy access on basic setups.
The difference shows in practice. Generic models might lag on big images. Stable Diffusion handles 512×512 pixels smoothly. It’s open-source, so developers tweak it freely.
The Art and Science of Prompt Engineering

The Art and Science of Prompt Engineering:
Positive Prompting: Guiding Image Creation
A positive prompt is your main text input. It tells the model what to create. For example, type “high-tech solar punk utopia in the Amazon forest.” The output shows futuristic tech amid green trees. Key words like “high-tech” add sleek designs. “Solar punk” brings eco-futuristic vibes.
Structure matters for better results. Start with the main subject, then add details. Include style, like “in cyberpunk art.” This guides the model precisely. Good prompts yield four varied images in seconds.
Test on Hugging Face: enter your text, hit generate. Watch how elements match your words. Refine by adding adjectives—turn basic into vivid.
Mastering Negative Prompting for Precision Control
Negative prompts exclude unwanted features. It’s like telling a child what not to do on an errand. Say “pink sports car on highway.” If you hate pink roads, add “no pink highway” in negative. The model skips those colors.
This gives full control. For deformed cars, type “deformed shapes” in negative. Outputs improve—cars look sleek, not twisted. Avoid “do not” words here; just list items to skip.
Examples help: exclude “humans” for empty scenes. Or “low quality” for sharp results. Practice this to avoid random flaws. It turns okay images into polished ones.
From Basic Prompts to High-Quality Generation
Start simple: “car on highway.” You get a vehicle with auto backgrounds. Add “pink sports car in traffic.” Now, it’s specific—pink body, busy roads. One word like “traffic” packs the scene.
Iterate for quality. If cars look off, negative “deformed cars.” Results sharpen up. Detailed prompts create pro-level art, like premium food bundles selling online.
Real tip: skilled users generate sellable images. One prompt yields bundles worth $43 each. In Pakistan, that’s about 12,000 PKR. Practice daily; outputs surprise you fast.
The Technical Backbone: Latent Diffusion Explained
Latent Diffusion Explained:
Why Traditional Diffusion is Computationally Expensive
Old diffusion models work pixel by pixel. A 1024×1024 image has over a million pixels. Each holds three colors—red, green, blue. Adding noise to all that drains compute power. Training takes days on strong machines.
This makes them slow and costly. Latency builds as the model processes everything. For everyday use, it’s impractical without big servers.
The Concept of Latent Space and Compression
Latent space hides details in fewer numbers. Think of it as packing a photo into a tiny file. You compress the image to vectors—say, thousands instead of millions. Key info stays; extras fade.
This is latent representation. It’s like hidden layers in neural nets. Stable Diffusion uses this for efficiency. Process noise in this small space, then unpack to full image.
Benefits? Saves 48 times the resources. Images form quicker, with less heat or power.
How Text Prompts Guide Latent Generation (Guided Diffusion)
Text turns into its own latent form, like an embedding. During denoising, the model gets this guide at each step. It steers noise removal toward your prompt.
Without it, outputs go random. With guidance, a “pink car” prompt shapes the result. This links words to visuals seamlessly.
Every time step pushes the model. Final image matches your description closely.
The Diffusion Process: Forward and Reverse
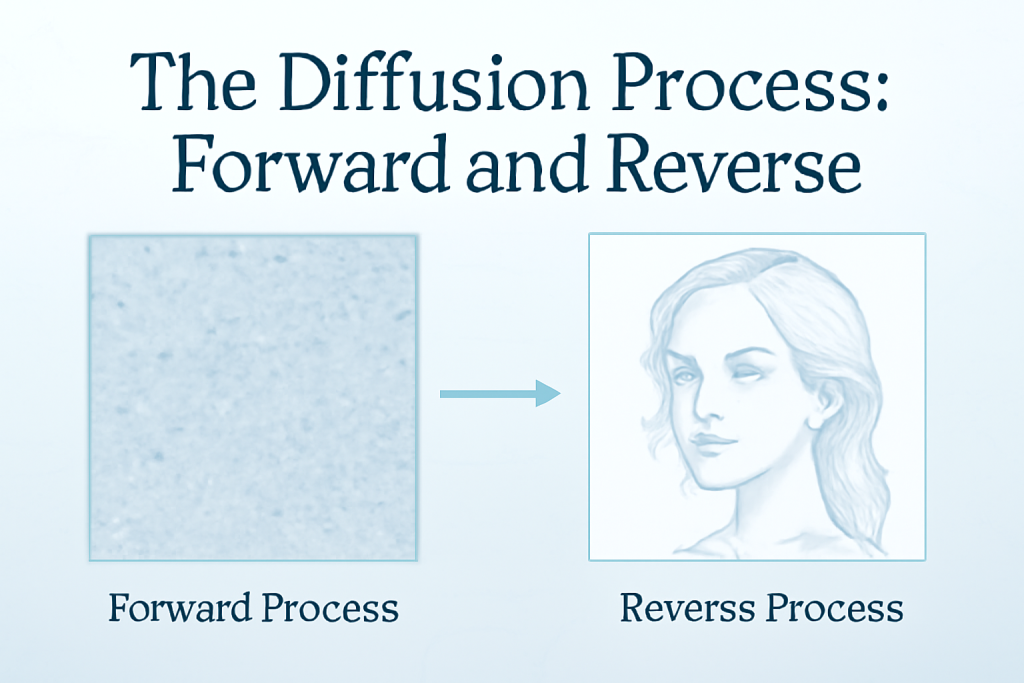
The Diffusion Processing:
The Forward Diffusion Process: Introducing Noise Systematically
Forward adds noise to a clean image. Start with a sharp photo. At each time step, sprinkle in static—like TV snow. Pixels blur gradually.
After many steps, it’s pure noise. This trains the model on destruction. An encoder helps compress during this.
It’s systematic, not random. The model learns exact steps to reverse later.
The Reverse Diffusion Process: Learning to Denoise
Reverse starts with noise. The model removes bits step by step. It guesses the original image underneath.
Training builds this skill. Input noise; output cleans to match known images. U-Net architecture handles the math here.
End with a clear picture. Feed any noise, get guided art.
Encoding and Decoding: The Role of the Autoencoder
Autoencoders pack and unpack data. Encoder squeezes image to latent. Decoder expands it back.
In diffusion, forward uses encoding for noise addition. Reverse relies on decoding for reconstruction. This duo makes the magic work.
It’s like a special encoder-decoder pair tailored for images.
Career Paths and Commercial Applications

Career Paths and Commercial Applications:
The Non-Technical Path: Prompt Engineering and Freelancing
Non-tech folks thrive with prompts. Hone skills to freelance fast. Generate client visuals without code.
Handle gigs like custom art or ads. Use platforms for quick jobs. Earnings come from quality outputs—sell bundles or edits.
Build a portfolio; clients pay for speed and creativity.
The Technical Path: Deep Dive into Mathematics and Code
Tech routes explore math basics. Learn vectors, latency, and comparisons. Cosine similarity helps measure likeness later.
Code custom pipelines. Train on billions of images. This leads to apps or tools.
It’s for builders wanting full control.
Domain Communication: Selling Your AI Skillset
Domain communication bridges tech and clients. Use field-specific words to impress. A doctor explaining symptoms builds trust fast.
In AI, drop terms like “latent diffusion” wisely. Mix simple talk with jargon. Clients feel you get their needs.
This sells your work better than skills alone. Non-tech managers earn big by talking the talk. You can too—practice vocabulary for deals.
Conclusion: Key Takeaways for AI Practitioners

Stable Diffusion turns text into images via clever diffusion. Noise spreads then clears, guided by prompts. Latent space cuts costs, making it fast and free.
Master positive and negative prompts for top results. Technical folks dive into math; others freelance with ease. Pair skills with strong communication to sell effectively.
Start practicing on Hugging Face today. Experiment with prompts, build your style. This tech opens doors—grab it and create.

